开发环境IDLE
exit() quit()
shift + 右键打开命令行ctrl + octrl + n #交互界面下ctrl + qalt + 3/4 注释与解除 注释:##f5 run
pypi.org 库网址
pip 命令
pip listpip install package1 package2pip install --upgrade packagepip uninstall package
模块导入
- 三种导入方式:
- 导入整个模块
import模块名as模块的别名(自定义) - 明确导入模块中的特定对象
from模块名import对象名as别名 - 导入特定模块中的所有对象
from 模块名 import *(不建议)
- 导入整个模块
变量及数据类型
命名规范
变量名必须以字母或下划线开头,不能以数字开头。·但下划线开头的变量在Python中有特殊含义。
变量名中不能有空格或标点符号。(括号、引号、逗号、斜线、反斜线、冒号、句号、问号等)。”
不能使用关键字作为变量名。关键字( keyword,也称为保留字,Python3版本中共有33个)。
不建议使用系统内置的模块名、类型名或函数名以及已导入的模块名及其成员名作为变量名,这会改变其类型和含义,甚至会导致4 其他代码无法正常执行。
变量名对英文字母的大小写敏感绶即要区分大小写。例如:a与A是不同的变量。
Python3版本可以使用中文。
变量的值是可以变化的,类型也随之发生改变。比如:
a = 3 ; a = "3"
小结:Python采用大、小写字母,数字,下划线,汉字等字符及其组合进行命名,长度没有限制,但是首字符不能是数字 ,不能出现空格与标点符号,大小写敏感,不能与关键字相同。(不建议使用中文等非英语语言字符)。
查看已有关键字
import keyword |
查看已有内置对象名
dir(__builtins__)
数字类型
整数
10 2 8 16进制转换:int() bin() oct() hex(),其中0b 0o 0x 代表2 8 16进制。int('111',6)
浮点数
float("3.5") = 3.5
复数
complex(3,5) = (3+5j)complex('3+5j') = (3+5j)
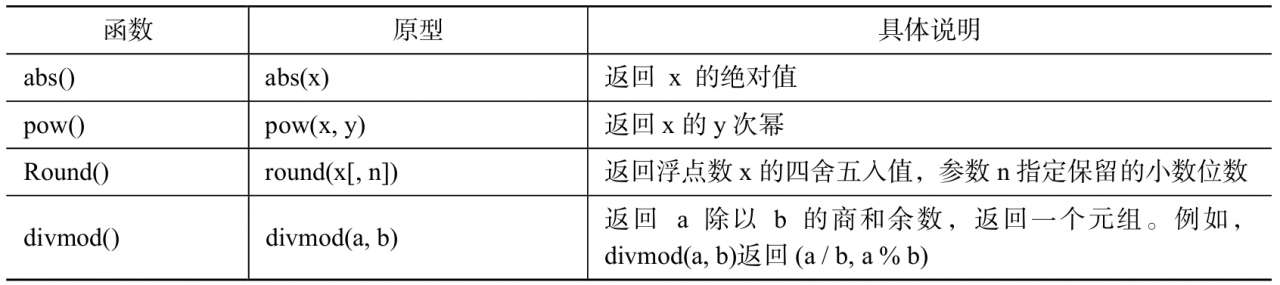
相关函数
abs()divmond()pow()round()

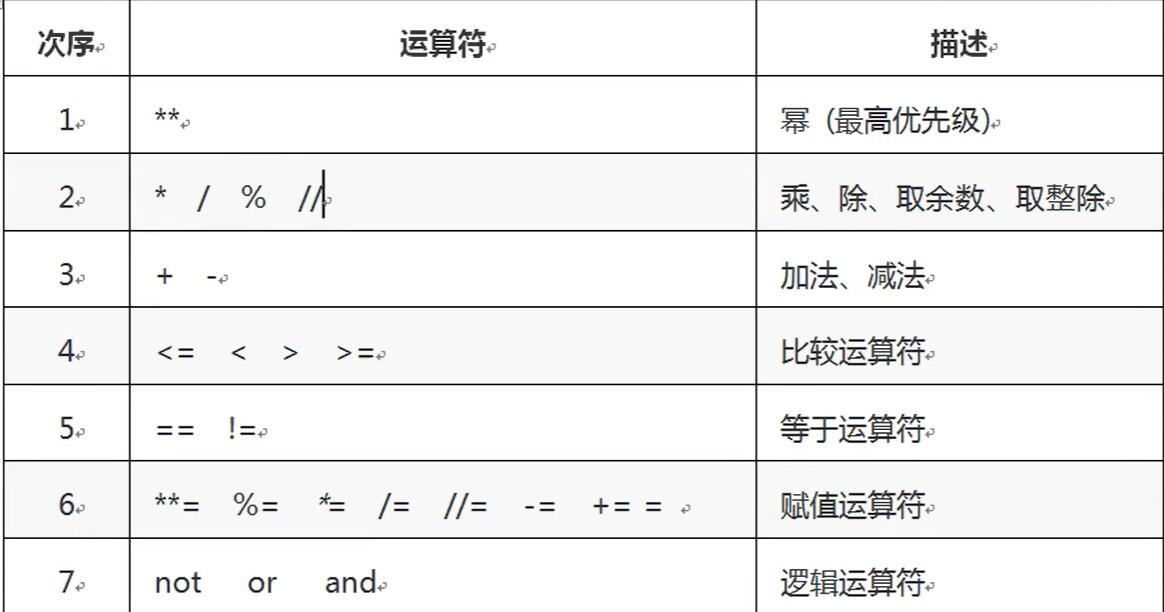
运算符
算数运算符
+ - * / // % **
字符串相加即为拼接,集合相减为差集,字符串*3即为重复3次
优先级
*** / % //+ -
比较运算符
== != > < >= <=
返回值为boolean
赋值运算符(加强赋值操作符)
= += -= *= /= //= %= **=
中间不能出现空格b *= 3+2 先算=右侧
逻辑运算符
and or not
x and y |
比较运算符优先于逻辑运算符
运算符优先级
成员运算符
in | not in
返回boolean
1 in (1,2) |
身份运算符
is | is notx is y等价于id(x) == id(y)
集合运算符
| & | | | - | ^ |
|---|---|---|---|
| 交集 | 并集 | 差集 | 对称差集 |
对称差集即为(a | b) - (a & b)
组合数据
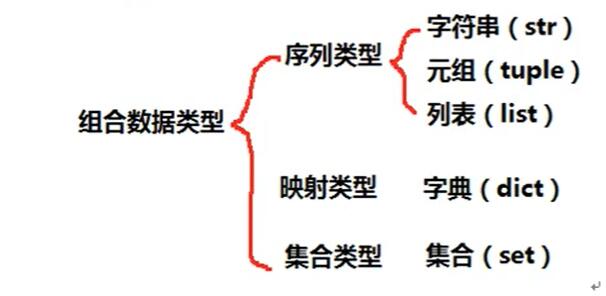
字符串
str():将其他序列转化为字符串,会把集合完全转化为字符串
比如
a = str(set1)
a[0]
‘(‘
把字典转化成str的时候好像冒号后面会多个空格
字符串的创建
- 交互式
a与print(a)的区别是少个‘’ - 多行字符串内敲入回车会换行,可以加
\防止换行。\n表示换行。 - 多行字符串用
'''三单'''或者"""三双"""具体可参考:《Python中单引号,双引号,3个单引号及3个双引号的区别》 - 反斜杠
\的用处- 续行符
- 转义符:
\n表示换行符
str = """他说:"你好。" """后面四个"必须分成1+3
字符串的索引与切片
- 索引
index - 切片
slice,适用于字符串、列表、元组- 格式:
字符串名[开始索引:结束索引:方向与步长] - 注意:
- 结束索引不包括在内,即左闭右开;步长默认为一。
- 从头开始:
str[:3:2] - 到末尾结束:
str[2::3]
- 格式:
- 由字符到索引
str.index('A')查询的是首次出现的index
字符串的运算符
| +: 拼接 | *: 重复 | 成员运算符:in/not in | 比较运算符:> < >=… |
|---|
字符串的比较标准:ASCII码,Unicode编码值
- 升序 A—Z—a—z
- 数字从小到大
- 若混合排序: 数字 < 大写字母<小写字母
- 多个字符串比较时,从首位开始逐步比较。
chr()返回Unicode编码值对应的字符ord()返回编码值,如ord('1')
字符串格式化(format())
'你好,我是{},是{}的爸爸。'.format('Linda','Mia')'你好,我是{1},是{0}的爸爸。'.format('Linda','Mia')
{}里面可以填写index,用来匹配format()里的参数,从0开始。'你好,我是{},{{是{}的爸爸。}}'.format('Linda','Mia')
当想输出{}的时候,需要写成{{}},此处{}用来转义。
此处有待补充
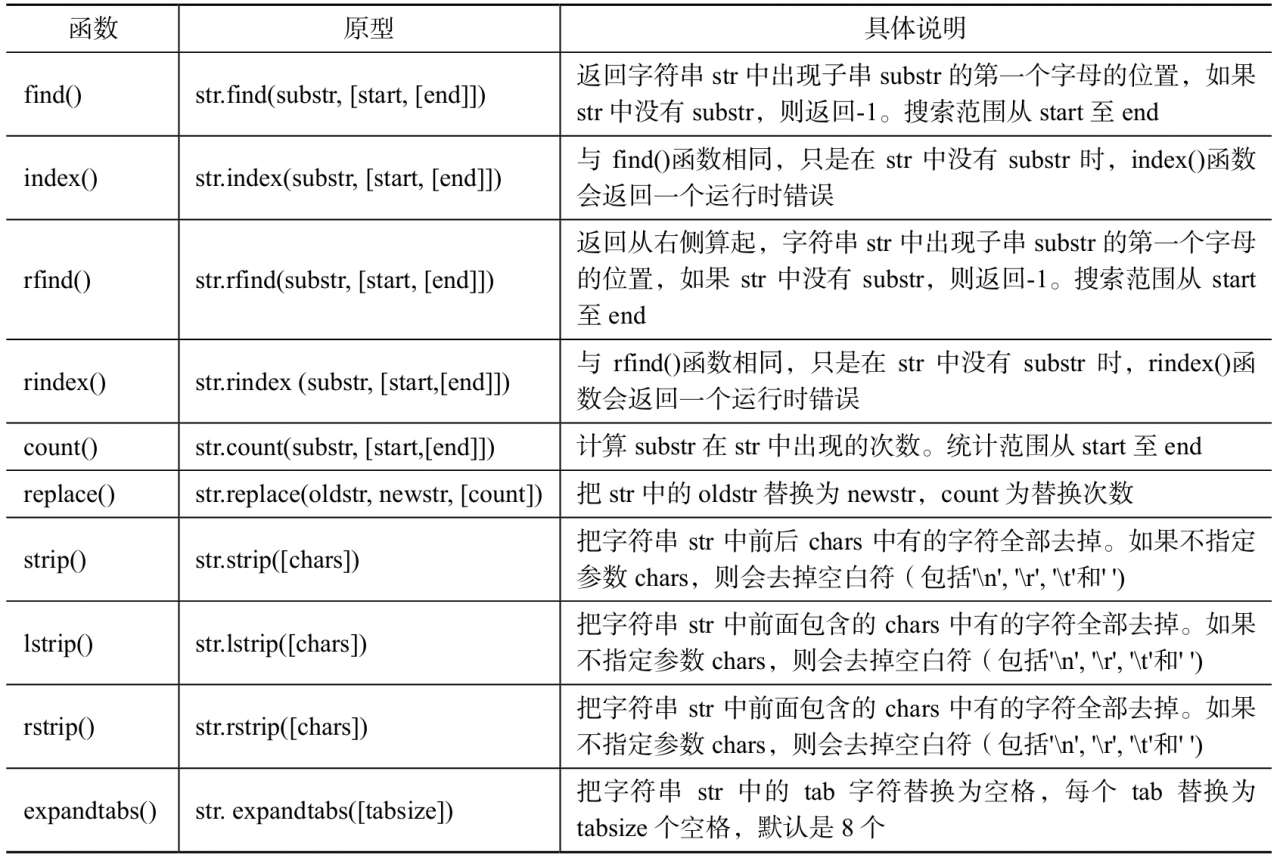
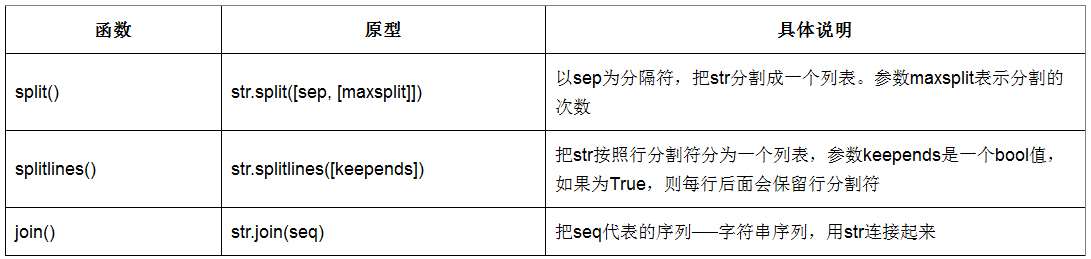
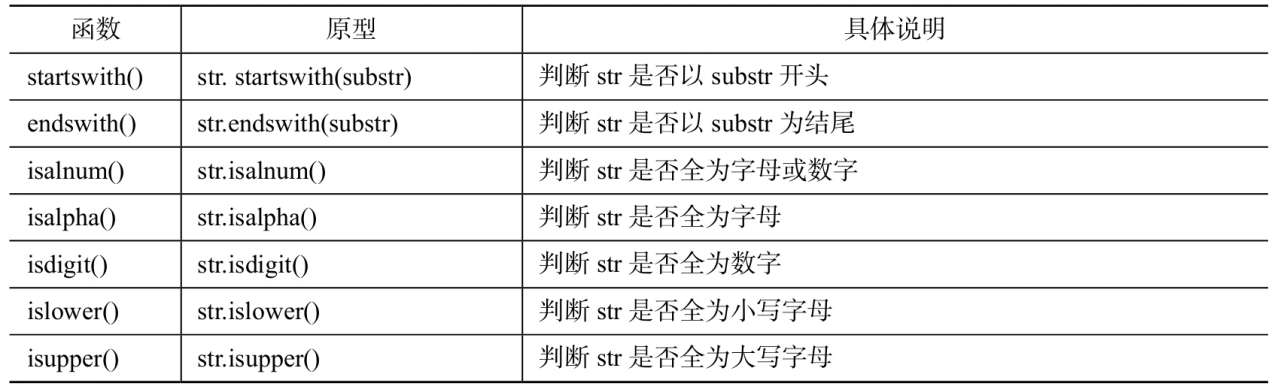
字符串函数汇总
- 参考:字符串常用方法汇总
eval()去掉最外侧的引号并以Python语句输出- 一些图片
元组
| (元组) | [列表] | {字典} | {集合} |
|---|---|---|---|
| 不可更改 | 可更改 | 可更改 | 可更改,元素不可重复 |
- 元组是不能修改的,只能再生成新的元组
tuple = () - 两个类型不一样
tuple = (1)tuple = (1,) - 取值
tuple[1]tuple[2:5] - 拼接
tuple[1:3]+ tuple[3:5]
注意单个元组如:tuple[2]不是元组,是不能用来和元组拼接的。 - 方法
len()max()min()tuple(seq).count().index()查第一次出现的数据的索引 - 比较
元组内部的元素一般为同一种,如果不统一的话在进行某些操作的时候会报错。 - 遍历
<!-- for -->
for i in range(len(tuple)):
print(i)
for i in tuple:
print(tuple[i])
<!-- while -->
i = 0
while i<len(tuple):
print(tuple[i])>列表
- 创建列表
- 普通创建
list = ['','',''...]list = [1,2,3...] - 由字符串创建
list1 = list('abcde')
- 普通创建
- 方法
- 增加
.insert(索引,数据) 指定位置插入
.append(数据) 末尾追加数据
.extend(列表2) 拼接列表,即为list1 + list2 - 删除
del list[索引] 删除指定元素
.remove(数据) 删除第一次出现的数据
.pop() 删除末尾的数据
.pop(索引) 删除指定数据
.clear() 清空 - 修改
list[索引] = 数据 - 查询
list[索引]
.index(数据) 第一次出现的索引
len() 长度
.count(数据) 统计次数 - 排序
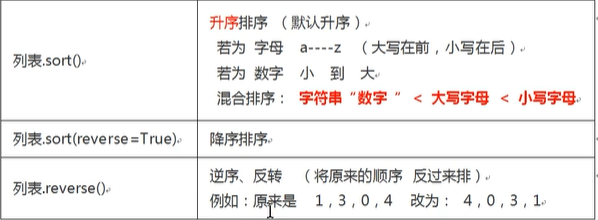
- 相加相乘
list1 + list2拼接list2 = list1 * 3复制三次 - 复制
- 增加
字典
del()popif '' in d:for key in d.keys():for value in d.values():.clear
list(dic) = list(dic.keys()) 只有keyslist(dic.values())list(dic.items())tuple 一样for x in dic:
print(x) #输出只有keysfor x in dic.items(): #输出键值对
while不能直接遍历字典 需要转化为tuple/列表,这样才有索引,才能通过索引遍历。
集合
集合中间只能包含不可变的数据:如数字、字符串、元组。(唯一性)
set1 = {1,2,3,4} |
字符串转化为集合会拆分字母,且自动去重,无序。字典转化为集合只会呈现keys。
>>> set(range(1,9)) |
| 表示 | 含义 | 方法 |
|---|---|---|
| s = s1 | s2 | 并集 | s1.union(s2) |
| s = s1 & s2 | 交集 | s1.intersection(s2) |
| s = s1 - s2 | 差集 | s1.difference(s2) |
| s = s1 ^ s2 | 两集合中不重复的元素 | s1.symmetric_difference(s2) |
参考1:python 集合比较(交集、并集,差集)
参考2:集合方法参考
函数
杂碎知识点
return多个返回值:return sum,product
返回值默认显示为元组(1,2)
还可以按需求为其它的形式如:
列表:return[sum,product]
基础操作
def fun1(x):help(fun1)dir(fun1)fun1.
作用域
| L | E | G | B |
|---|---|---|---|
| 局部 | 闭包外 | 全局 | 内建 |
函数内部声明global aif elif else try except for while不会引入新的作用域,其中定义的变量外部也可以访问。
基本函数
斐波那契数列的递归函数input() | age = input('your age:')raw_input()只存在于python2,不管输入什么的都是字符串print()int()print(value1,value2,value3...,step = '\t',end = '\n', file = 'sys.stdout')
for i in range(1,5) |
写入文件
with open ('test.txt','w') as file01: |
内置函数
工厂函数:list() tuple() dict() set() int() str()
数学函数
模拟笔记
杂碎知识点记忆
eval('代码') 执行其中的代码,并返回值str.split() 分割,返回列表,默认以空格分割{:->25,}.format() 格式化输出,注意->一起使用
python3.x input() 返回值是str,如需格式化输出等,可用int()、eval()转换为整数 ,eval()就是去掉引号
<填充><对齐/<宽度><,><.精度><类型>等六个字段,for i in range() i从0开始b = 1,2,3type(b) = tupletype(eval('1,2,3')) = tuplejieba.lcut() 返回值是列表list.reverse() 会改变原来的列表,而且没有返回值
参考1:print(s[::-1])
参考2同时给多个变量赋值a, b = 0, 1random 之能生成0.0-1.1之间的数,randint可以指定(1,2)经过实测,是[1,2]
ifxxx: |
print("{:+^11}".format(chr(n-1)+chr(n)+chr(n+1)))字符串直接相加就行
输入多个数 a,b,c = eval(input())try exceptint(a) == aturtle.sethturtle.leftstr.split不改变原来值
python3排序 sorted(key=lambda)
常用的用字典统计个数d[i] = d.get[i]+1
如果是readlines读写进来的列表,其中的元素含有\n字符,算作一个字符,素以向字典添加的时候需要去掉,即为d[i][:-1] = d.get[i][:-1]+1if len(name.split()) == 1: 记录一行有两个名字的有效票数问题
判断数据是否在字典里,不管是key还是value都可以用if data in d:
print输出多个数据的时候,可以用format格式化输出 print('{}{}{}'.format(a,b,c))
文件内容的遍历:
file = open('xxx.txt','rb') |
盲点
- 位运算符
- 优先级
- 可变长参数
- 格式化输出
- 序列的方法
- 用字典统计数目
- 字符串中的数字怎么比较
- format参数
- 字符串的一些函数
软件技术基础
软件 = 程序+ 文档 = 数据结构+算法+文档
选择题笔记
x*y的作用是计算x的y次幂。
x//y的作用是计算x与y的整数商,即不大于x与y之商的最大整数。
x%y的作用是计算x与y之商的余数。
表达式中的运算符中,\*的运算级最高,所以先计算4**2,即3*4**2//8%7=3*16//8%7=48//8%7=6%7=6。
C语言是静态编译语言,Python语言是脚本语言 静态语言和脚本语言,静态语言采用编译方式执行,脚本语言采用解释方式执行。
Python语言中的浮点数类型必须带有小数部分,小数部分可以是0。
一般代码不需要缩进,顶行编写且不留空白。当表示分支、循环、函数、类等程序含义时,在if、while、for、def、class等保留字所在完整语句后通过英文冒号结尾并在之后进行缩进,表明后续代码与紧邻无缩进语句的所属关系。
代码编写中,缩进可以用Tab键实现,也可以用多个空格(一般是4个空格)实现,但两者不混用。不会增加编程难度。
Python采用大写字母、小写字母、数字、下划线和汉字等字符及其组合进行命名,但首字符不能是数字。
Python保留字是大小写敏感的,True是保留字,true不是。
sum不是保留字,可以被当做变量使用。finally是保留字。
id()函数是Python内置函数之一,作用是获取对象的内存地址,返回对象的内存地址(是一个正整数)。
Python语言的三个重要特点:
(1)通用性:Python语言可以用于几乎任何与程序设计相关应用的开发,不仅适合训练编程思维,更适合诸如数据分析、机器学习、人工智能、Web开发等具体的技术区域。
(2)语法简洁。
(3)生态高产:Python解释器提供了几百个内置类和函数库,此外,世界各地程序员通过开源社区贡献了十几万个第三方函数库。
除此之外,还有一些具体特点:
(1)平台无关。
(2)强制可读。
(3)支持中文。
count
>>> import keyword |
type(type(‘45’))输出为<class ‘type’>。
以下保留字不用于循环逻辑的是trys[0:4]表示截取字符串正向第1个字符1到正向第5个字符5(不包括5)之间的字符,即’1234’。
乘除和取模取余同级先计算5%6*2//8=5*2//8=10//8=1,再计算3+1=4。
**是数值运算操作符。
&是按位与运算符,&=则是对应的二元操作符。
^是按位异或运算符。
保留字大小写敏感,False是保留字,false不是保留字。
if不用于异常处理逻辑,用于分支结构。tryelsefinally都用于异常处理
python 不是网络编程语言
Python中出现SyntaxError一般表示语法错误,如未在if , elif , else , for , while , class ,def声明末尾添加”:”,导致该语句无法解释执行。
int()函数用于将一个字符串或数字转换为整型,字符串’100/3’中有”/“,该文本不能转化成数值,参数无效,会报ValueError的错误。
random.random()表示取随机数,数值的类型是float型,
uniform(a,b):生成一个[a,b]之间的随机小数,3.993002365820678超出了范围。
判断字符串内是否有子字符串,可以用if xx in str:或if str.coune('xx') >0:ls.append(line.strip('\n').split(','))
👇👇👇这是练习的一道题,卡在一个点出不来了记录一下,简而言之就是👇👇👇
- 建议把f.read()保存到一个变量里,然后f.close()。
- List.sort会改变原来的列表,而且没有返回值!!!!😭打开
import jieba
d = {}
def print_most_word (path,year):
f = open(path,'r')
txt = f.read()
f.close()
wordList = jieba.lcut(txt)
for word in wordList:
if len(word) >1:
d[word] = d.get(word,0)+1
dls= list(d.items())
dls.sort(key = lambda x:x[1],reverse = True)
print(str(year)+':',end='')
for i in range(10):
if i ==:
print('{}:{}'.format(dls[i][0],dls[i][1]))
continue
print('{}:{},'.format(dls[i][0],dls[i][1]),end='')
print_most_word('data2018.txt',2018)
print_most_word('data2019.txt',2019)txt的时候看一下编码格式如果是utf-8那么打开的时候要注意是:f = open('data.txt','r',encoding='utf-8')
注意如果一不小心把r写成了w,文件就会清空了!!
模拟考试知识点总结
遍历字符串:for i in string1:for i in len(string1):
统计字符串的某个字符的个数:sting.count('xxx')
格式化输出的进制以及大小写
字符串索引是[index]
《python list转换字符串报错TypeError: sequence item 0: expected str instance, int found》
<!-- 提取示例 --> |
turtle.seth()是设置turtle的角度,turtle.left()是改变角度
f = open('论语-网络版.txt','r',encoding = 'utf-8') |
字典里面的东西写进去:
for key in d: |
字符串的截取:string[:2]
表示第0和第1.
d = input() #当输入值可能有小数时可以用eval |
s = input() |
n=float(input()) # float(xxx)其中的xxx必需全是数字,可以是小数 |
all(x):组合类型变量x中所有元素都为真时返回True,否则返回False;若x为空,返回True。
any(x):组合类型变量x中任一元素都为真时返回True,否则返回False;若x为空,返回True。
y中第一个元素为一个空格,第二个元素为空,即null,所以第一个元素为真,第二个元素为假,all(y)输出False,any(y)输出True。
如果一个函数需要以多种形式来接收实参,定义时一般把位置参数放在最前面,然后是默认参数,接下来是一个星号的可变长度参数,最后是两个星号的可变长度参数。
例:def foo(x,args,*kwargs):
Python为源文件指定的默认字符编码是__。(UTF-8)
round(x,d):对x四舍五入,保留d位小数,无参数d则返回四舍五入的整数值。
当文件以文本方式打开时,读写按照字符串方式;当文件以二进制方式打开时,读写按照字节流方式。
创建写模式x,文件不存在则创建,存在则返回异常FileExistsError。
打开并关闭文件的操作,需要文件的路径名,由于”"是字符串中的转义符,所以表示路径时,使用”\“或”/“代替”"。
第三方库
网络爬虫方向
requests
scrapy
pyspider
数据分析方向
numpy
pandas
scipy
文本处理方向
pdfminer
python-docx
beautifuisoup4
数据可视化方向
matplotlib
seaborn
mayavi
用户图形界面方向
PyQt5
wxPython
PyGTK
机器学习方向
scikit -learn
TebsorFlow
mxnet
web开发方向
Diango
Pyramid
flask
游戏开发方向
Pygame
Panda3D
cocos2d
考完总结
其实吧,不用看那么多视频,就那个模拟考软件,把题库完完整整刷完搞懂就行了,考试完全没问题(我不会告诉你都是原题的)。
额外服务
邮件服务
<!-- 邮件服务 --> |
自动更新更新时间
<!-- 自动更新更新时间 --> |


v1.5.2